Ce produit participe actuellement à une offre promotionnelle.
Ajouter au panier
Commencer la commande
Acheter maintenant
(En stock)
Commande personnalisée
Paiement :
Livraison :
De
--
À
--
Veuillez nous contacter pour confirmer les frais de livraison
description1
Fermeture à glissière. Pulls sportifs 1/4 zip pour hommes. Tissu extensible, léger, à séchage rapide pour des performances supérieures. COUPE RÉGULIÈRE - Tailles standard américaines. Une coupe athlétique qui épouse le corps pour une grande amplitude de mouvement, conçue pour des performances optimales et un confort toute la journée. CARACTÉRISTIQUES - Fermeture quart de zip ; Passes pouces sur les manches longues pour les maintenir en place pendant l'entraînement.
Défis de l'intégration de données traditionnelle
①
Données non en temps réel
Les données transférées via ETL accusent un retard par rapport à celles des systèmes de production et nécessitent souvent un retraitement en raison d'incohérences ou de problèmes de qualité.
②
Coûts de mise en œuvre élevés
La centralisation des données provenant de centaines de bases de données en utilisant Schema-on-Write exige d'énormes ressources en temps, main-d'œuvre et finances tout en étant incapable d'atteindre une synchronisation en temps réel.
③
Goulots d'étranglement de performance
Généralement, chaque base de données métier doit assumer le reporting des données, la synchronisation de la plateforme d'intégration et d'autres tâches. Les processus ETL alourdissent les bases de données sources, dégradant les performances opérationnelles.
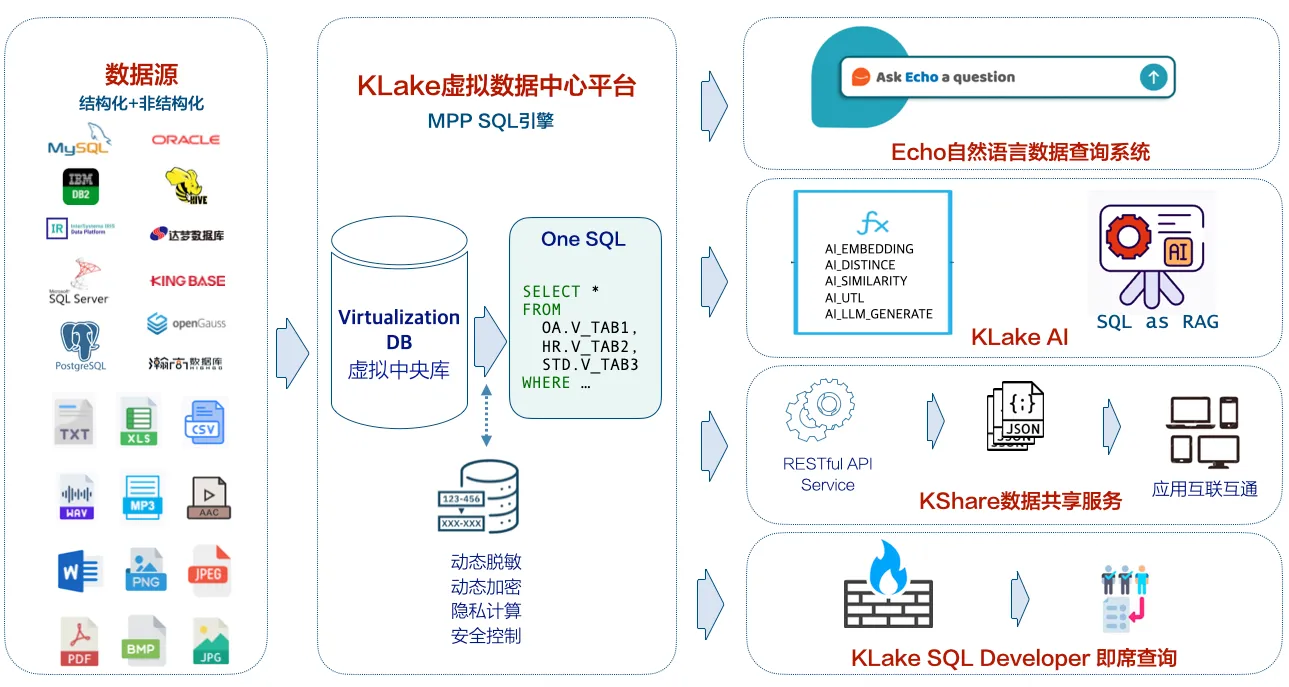
KLake Hub de Données Virtuelles
Contrairement à la dépendance de l'ETL au mouvement physique des données, KLake utilise la virtualisation des données pour créer un 'tissu de données' invisible qui unifie les données en temps réel de sources disparates. Cette couche virtuelle fournit une vue holistique et dynamique des données d'entreprise sans réplication physique.
①
Schéma à la lecture :
Il analyse dynamiquement les schémas de données pendant les requêtes, effectue des transformations et des filtres à la demande, et unifie les bases de données organisationnelles en une source logiquement centralisée.
②
Rapports et analytiques multi-sources :
Il permet des requêtes croisées en temps réel entre bases de données pour les rapports, éliminant ainsi les données obsolètes ou inexactes des référentiels intermédiaires.
③
Décharger les bases de données sources :
Il analyse le SQL en sous-requêtes, les exécute via des pilotes ODBC à travers les systèmes sources, et effectue des calculs (jointures, agrégations) au sein du cluster MPP de KLake — réduisant la charge sur les bases de données de production.
④
Gestion des métadonnées pilotée par IA :
Il identifie automatiquement les structures de table, les définitions de champ et les relations en utilisant des outils de découverte de métadonnées alimentés par l'IA, minimisant la configuration manuelle.
⑥
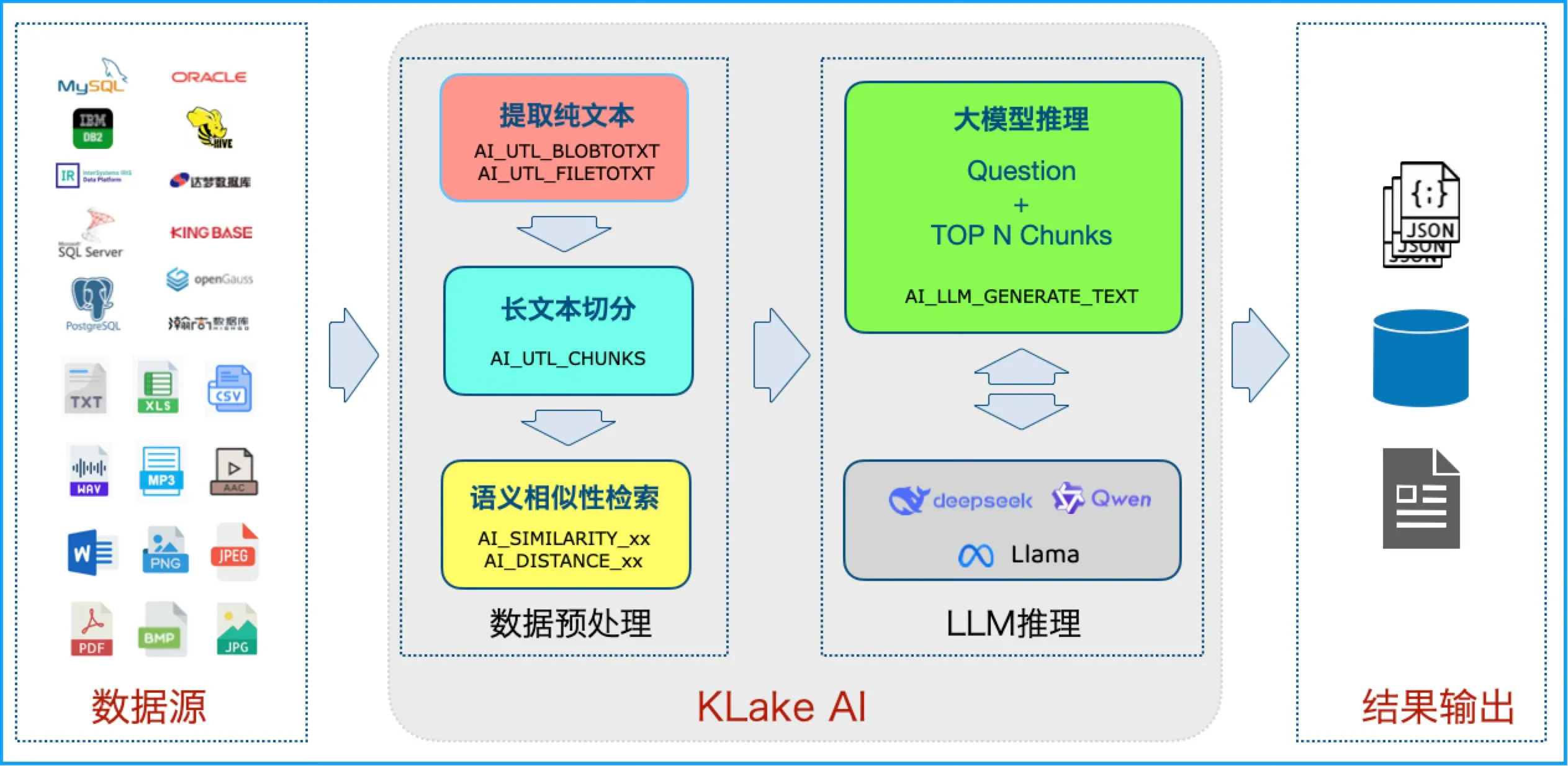
Bibliothèque sans vecteur :
Dites adieu aux problèmes de cohérence complètement, grâce aux fonctions SQL AI_EMBEDDING_DENSE et autres, conversion en temps réel de texte/PDF/WORD/image/audio en vecteur sans stockage persistant.
⑦
SQL est l'IA, zéro programmation pour réaliser l'application de scène complète
a> Recherche sémantique :
AI_SIMILARITY_DENSE('patient se plaint de douleurs thoraciques', texte du dossier médical, 'cos') recherche des dossiers médicaux similaires en quelques secondes ;
b> Analyse de documents : AI_UTL_BLOBTOTXT(rapport CT, 'PDF', TRUE) Extrait le texte PDF/image (OCR pris en charge) ;
c> Q&A RAG : AI_LLM_GENERATE_TEXT('DeepSeek-chat', < question épissée + fragment de similarité >) Produit des rapports de résultats et des suggestions.
identifier les données pertinentes.
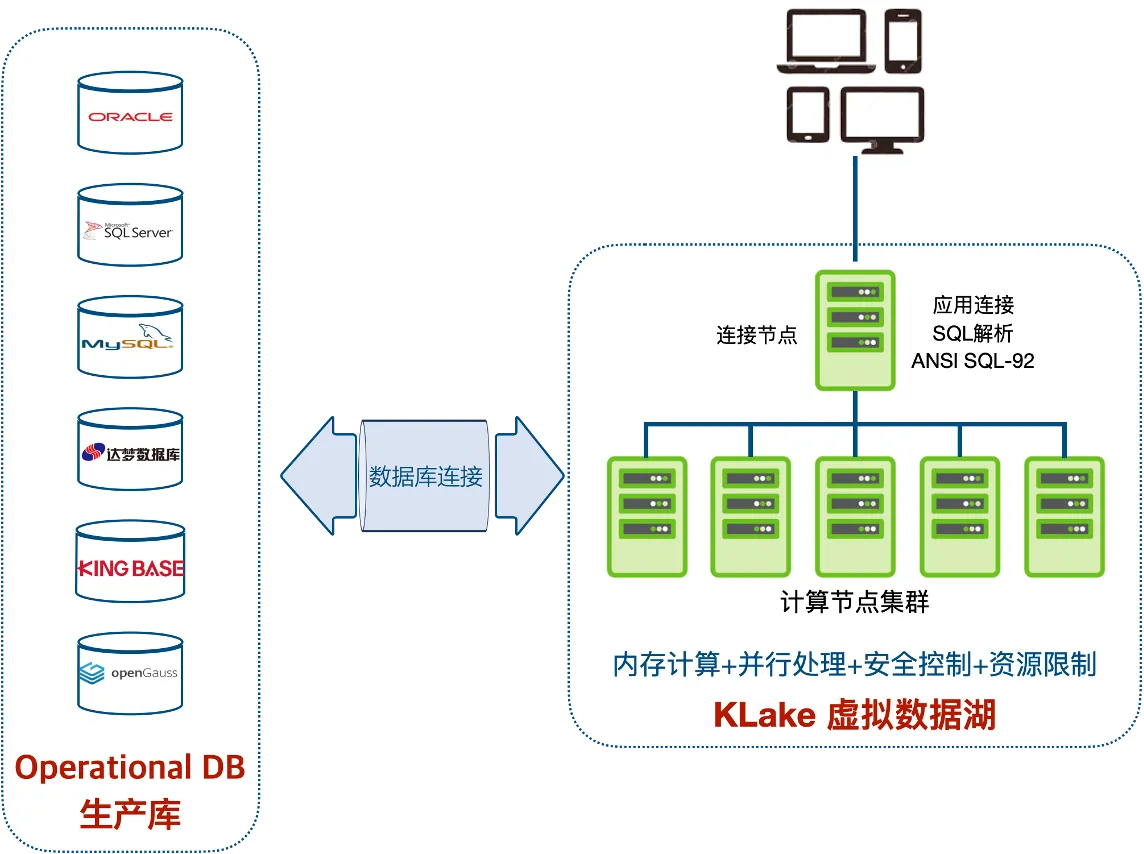
Architecture Technique KLake
KLake est un cluster de calcul SQL basé sur le traitement massivement parallèle (MPP). Il ne stocke pas de données mais analyse/exécute dynamiquement des requêtes SQL et renvoie les résultats. La plateforme offre des contrôles de sécurité centralisés et une gestion des ressources
Sources de données prises en charge
Au moins les sources de données suivantes sont prises en charge :
Intégration d'outils tiers
KLake s'intègre avec les outils BI/ETL via des pilotes JDBC/Python, permettant un accès aux données en temps réel sans déplacement physique. Les outils pris en charge incluent :
① FineReport
Les utilisateurs peuvent obtenir des performances SQL 3 fois plus rapides et visualiser des données de niveau téraoctet en temps réel en interrogeant les sources mappées par KLake (par exemple, HIS, PACS).
②
Metabase
Les utilisateurs peuvent écrire du SQL dans Metabase pour analyser des données en temps réel sur les
systèmes connectés à KLake
.
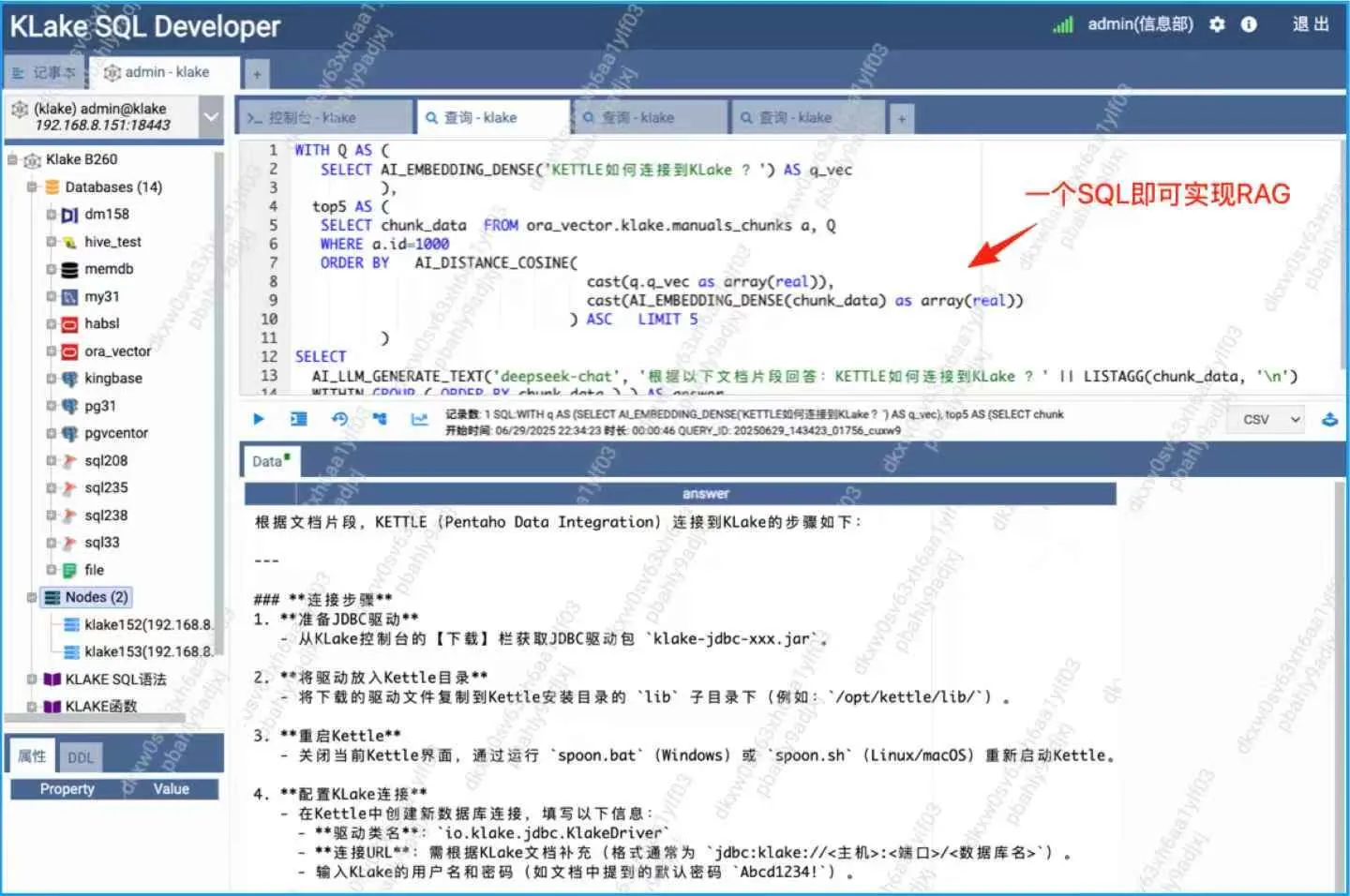
③ Kettle
Les utilisateurs peuvent planifier des tâches ETL dans Kettle pour interroger KLake afin de l'extraction et du reporting en temps réel des données.
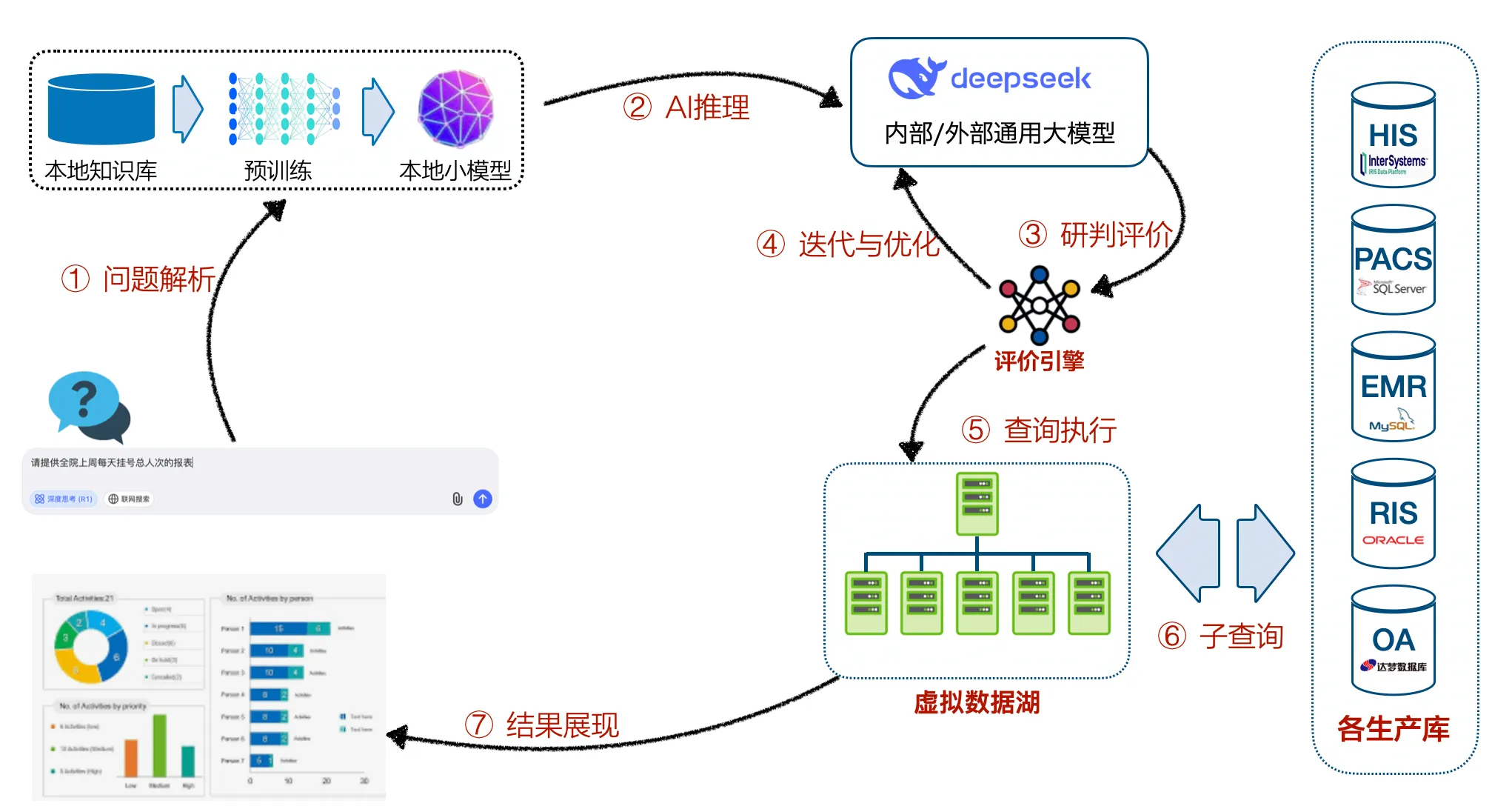
Système de Rapport en Langage Naturel
Propulsé par le LLM open-source DeepSeek R1, ce système permet aux utilisateurs d'interroger les rapports d'entreprise via le langage naturel. Principales fonctionnalités :
Compréhension du langage naturel :
Traiter des requêtes comme 'Afficher les performances du département du mois dernier.'
Analyse multidimensionnelle :
Filtrer par temps, département ou métriques.
Visualisation :
Présenter les résultats sous forme de graphiques ou de texte.
Optimisation continue :
Améliorer la précision via les retours utilisateur.
Base de connaissances locale :
Construit une vue de métadonnées unifiée pour la récupération de données privées.
Petit modèle local :
Entraîné sur la base de connaissances pour permettre une recherche sémantique vectorielle.
LLM d'entreprise (DeepSeek) :
Combine les connaissances locales avec le raisonnement du LLM pour la conversion langage naturel vers SQL.
Moteur d'évaluation :
Valide la précision SQL avant l'exécution.
Accès multiplateforme :
Interfaces web et mobiles pour une interaction utilisateur transparente.
Afin de réaliser les fonctions ci-dessus, ce schéma adopte l'architecture technologique Data Fabric. Comparé au mode traditionnel ETL et entrepôt de données, KLake connecte dynamiquement diverses bases de données dans l'entreprise via un réseau intelligent piloté par la gestion des métadonnées, évitant les liens intermédiaires tels que la migration et le nettoyage des données, et améliorant significativement la réactivité et la cohérence de l'utilisation des données.
Avantages Quantifiables
Intégration Plus Rapide :
La virtualisation des données de KLake permet une intégration rapide de sources de données diverses, augmentant la vitesse de consolidation des données par 3×.
Optimisation des Stocks :
Les vues unifiées en temps réel améliorent la précision et la rapidité des stocks, augmentant l'efficacité de 40 % et réduisant les déchets.
Coûts d'Exploitation et de Maintenance Réduits :
Éliminer la réplication des données et les liens point à point simplifie l'architecture, réduisant les coûts opérationnels de 50 %.
Rapports Plus Rapides :
Les requêtes haute performance et les outils de visualisation réduisent le temps de génération des rapports de plusieurs heures à quelques minutes, améliorant l'efficacité de plus de 60 %.
Accès aux Données Plus Rapide :
Les requêtes inter-systèmes en temps réel réduisent les temps de réponse de 80 %, permettant des insights commerciaux plus rapides.
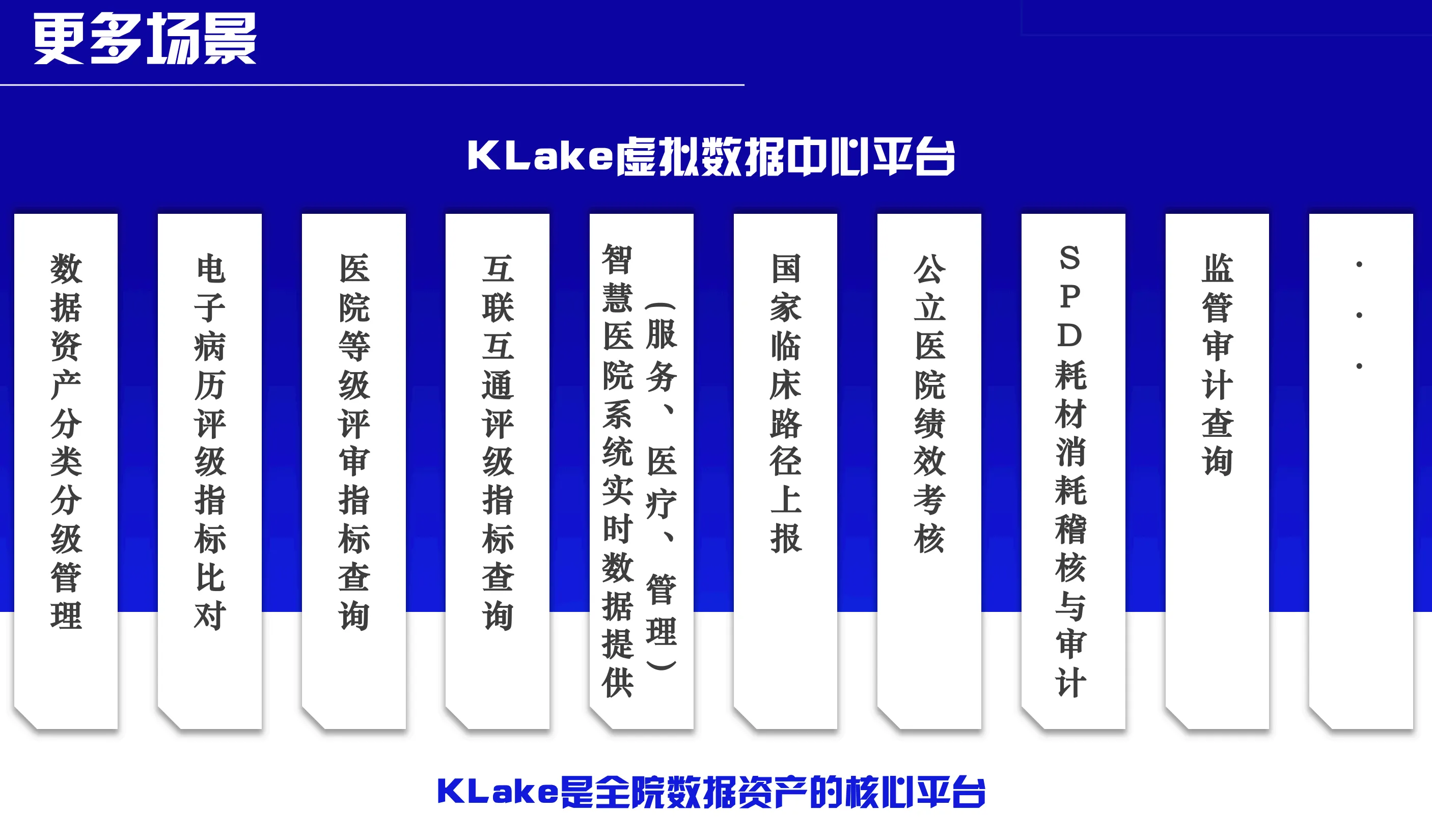
Cas d'utilisation de KLake dans les soins de santé
①
Soulager la charge de la base de données de production :
KLake décharge les calculs SQL des systèmes HIS/PACS vers le cluster MPP de KLake. Le reporting quotidien des données des systèmes HIS et PACS, ainsi que la synchronisation de diverses données, ont submergé la base de données de production principale.
②
Évaluation comparative intersystèmes :
Les utilisateurs peuvent exécuter des comparaisons SQL uniques sur plusieurs bases de données pour le classement des hôpitaux (par exemple, l'interopérabilité des DSE).
③
Requêtes en langage naturel :
Les utilisateurs peuvent saisir des exigences de requête en langage courant (comme 'Rechercher le nombre de consultations d'urgence le mois dernier') ou saisir des mots-clés de diagnostic (comme 'patients diabétiques de type 2'), et le système analysera automatiquement l'intention et renverra les résultats.
④
Données en temps réel pour les hôpitaux intelligents :
KLake unifie les données de l'ensemble de l'hôpital dans une base de données virtuelle pour alimenter les applications de santé intelligentes en temps réel. KLake consolide toutes les ressources de base de données de l'hôpital en une seule base de données virtuelle, résolvant ainsi parfaitement les problèmes de performance en temps réel et d'exhaustivité des données, et servant de fondation d'infrastructure de données centrale pour l'hôpital.
Nous prenons en charge les échantillons de commande, la personnalisation, la vente en gros directe et le paiement complet. Si le produit que vous recherchez ne dispose pas de contenu personnalisé correspondant, veuillez remplir le formulaire ci-dessous pour nous contacter, et nous répondrons dès que possible.


.webp)