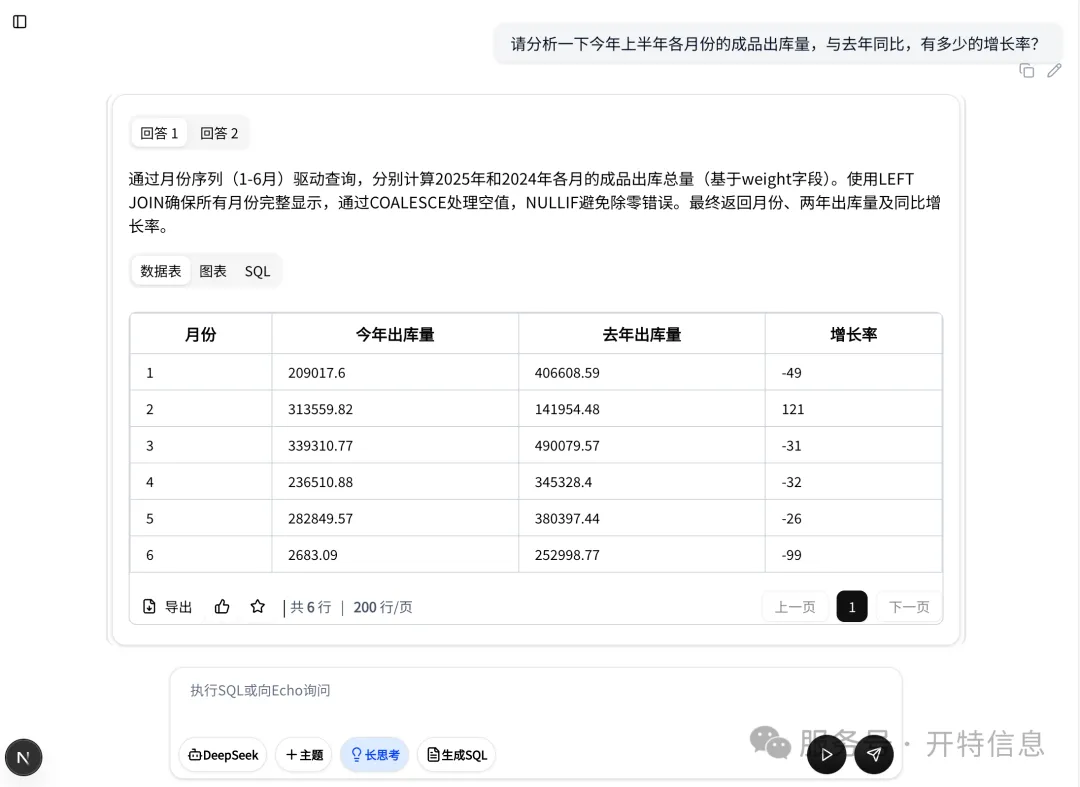
Comment permettre au personnel non technique d'interroger facilement les données est devenu le problème le plus pressant pour chaque organisation
Les méthodes traditionnelles d'interrogation des données reposent fortement sur les départements informatiques et le personnel technique, entraînant des temps de réponse lents et une faible efficacité. Aujourd'hui, le nouveau système lancé par Te Information
Echo Natural Language Data Query System
redéfinit la relation entre les humains et les données grâce à l'interaction conversationnelle.
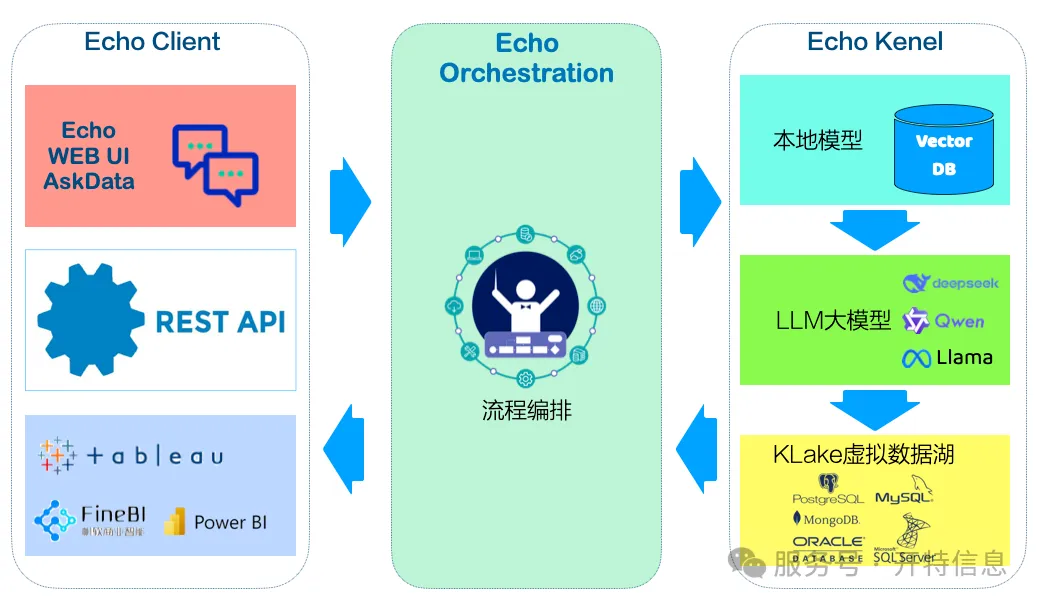
Echo est une plateforme d'interrogation de données en langage naturel de niveau entreprise. Tirant parti de puissantes capacités de compréhension sémantique et de raisonnement sur les connaissances locales, elle permet aux utilisateurs d'effectuer des requêtes de données complexes entre bases de données et entre tables, ainsi que de générer automatiquement des instructions SQL ou de renvoyer directement les résultats—
simplement en 'posant des questions' dans un langage quotidien
. Il n'est pas nécessaire d'apprendre le SQL ; le personnel non technique peut facilement démarrer et 'interroger les données comme en discutant', réalisant véritablement la vision de 'chacun peut être un analyste de données'.
Dans les modèles traditionnels, l'interrogation des données est souvent confrontée aux défis suivants :
-
Aucune compétence en programmation, aucun moyen de commencer à interroger
: La plupart des utilisateurs métier ne comprennent pas le SQL, encore moins les structures de bases de données.
-
Contraintes des ressources informatiques, réponses lentes
: Les ingénieurs sont coincés à traiter un flot de demandes de données ad hoc, noyés dans une 'mer de besoins'.
-
Données dispersées, intégration difficile
: Les silos de données à travers plusieurs systèmes rendent l'analyse entre bases de données des problèmes métier presque impossible.
-
Seuils de formation élevés, déploiement lent
: De nombreuses solutions Text2SQL nécessitent de grands volumes de données d'entraînement, entraînant des cycles de déploiement longs et des coûts élevés.
Echo a été créé pour résoudre complètement ces problèmes !
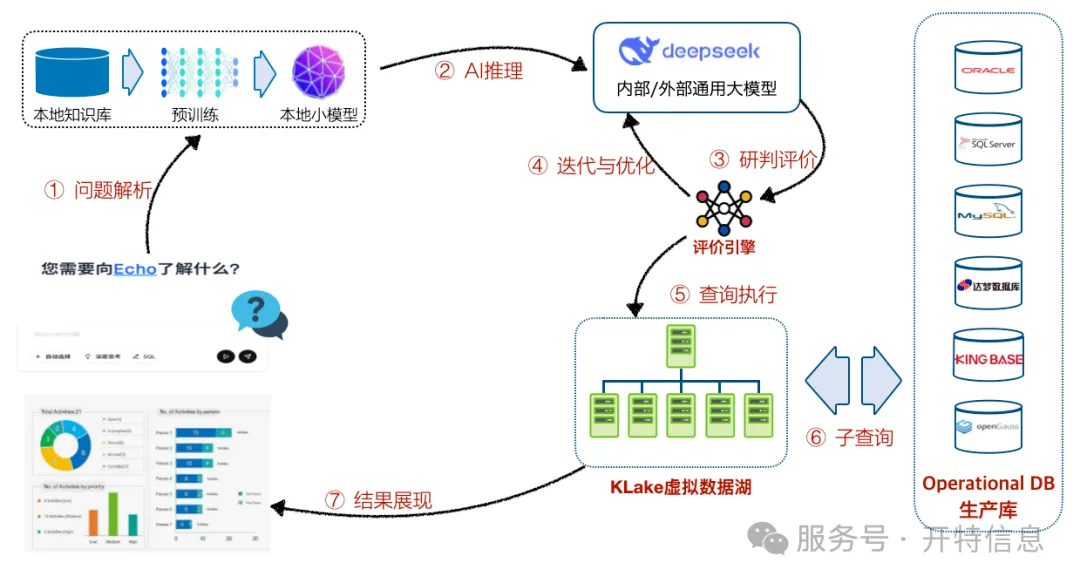
Echo ne 'comprend' pas seulement le langage naturel mais dispose également de solides capacités d'adaptation aux données et de performances de requête efficaces :
-
Prise en charge étendue des sources de données
: Compatible avec les bases de données principales telles que ORACLE, SQL Server, MySQL, DB2, Dameng, Kingbase et openGauss, ainsi que les formats de fichiers comme Excel et CSV—s'adaptant aux données hétérogènes multi-sources.
-
Capacité de requête inter-bases de données
: Une seule question utilisateur peut interroger simultanément plusieurs bases de données, permettant une véritable 'analyse collaborative inter-systèmes'.
-
Présentation directe des résultats ou génération de SQL
: Il peut produire des résultats visualisés pour que les utilisateurs métier les utilisent directement, ou générer des instructions SQL pour que le personnel technique les affine davantage.
-
Moteur MPP haute performance
: Basé sur une architecture de traitement massivement parallèle (MPP), les requêtes ont un impact minimal sur les performances des bases de données sources.
-
Prêt à l'emploi sans formation requise
: Aucun grand volume de données historiques de questions-réponses n'est nécessaire pour le déploiement. Il offre une forte adaptabilité et peut être mis en œuvre de manière flexible dans divers scénarios métier.
-
Reconnaissance sémantique floue et prédiction multi-chemins
: Même si une description de question est peu claire, le système fournit plusieurs réponses alternatives basées sur l'analyse sémantique, aidant les utilisateurs à clarifier progressivement leurs intentions.
L'application d'Echo non seulement améliore considérablement l'efficacité des données, mais transforme aussi fondamentalement la manière dont les données sont utilisées dans les entreprises :
-
Libérer les ressources TI pour se concentrer sur la gouvernance
: Les équipes TI ne sont plus bloquées à traiter passivement les demandes de données ; au lieu de cela, elles peuvent se concentrer sur la gouvernance et la standardisation des données.
-
Autonomiser les utilisateurs métier pour accélérer les temps de réponse
: Le personnel métier peut accéder aux données clés par lui-même sans attendre, accélérant la prise de décision.
-
Améliorer l'utilisation des données
: Le passage de 'attendre que d'autres interrogent' à 'demander activement' améliore la conversion des données en valeur.
-
Améliorer l'audit de sécurité et le contrôle des autorisations
: Il prend en charge l'audit de toutes les activités de requête et s'intègre aux systèmes d'autorisation pour garantir le respect du principe du moindre privilège.
À l'avenir, l'interrogation des données ne sera plus une compétence exclusive du personnel technique mais une compétence de base pour tous les participants commerciaux. Echo a été développé pour briser les barrières techniques et mettre véritablement en œuvre 'l'équité des données'.